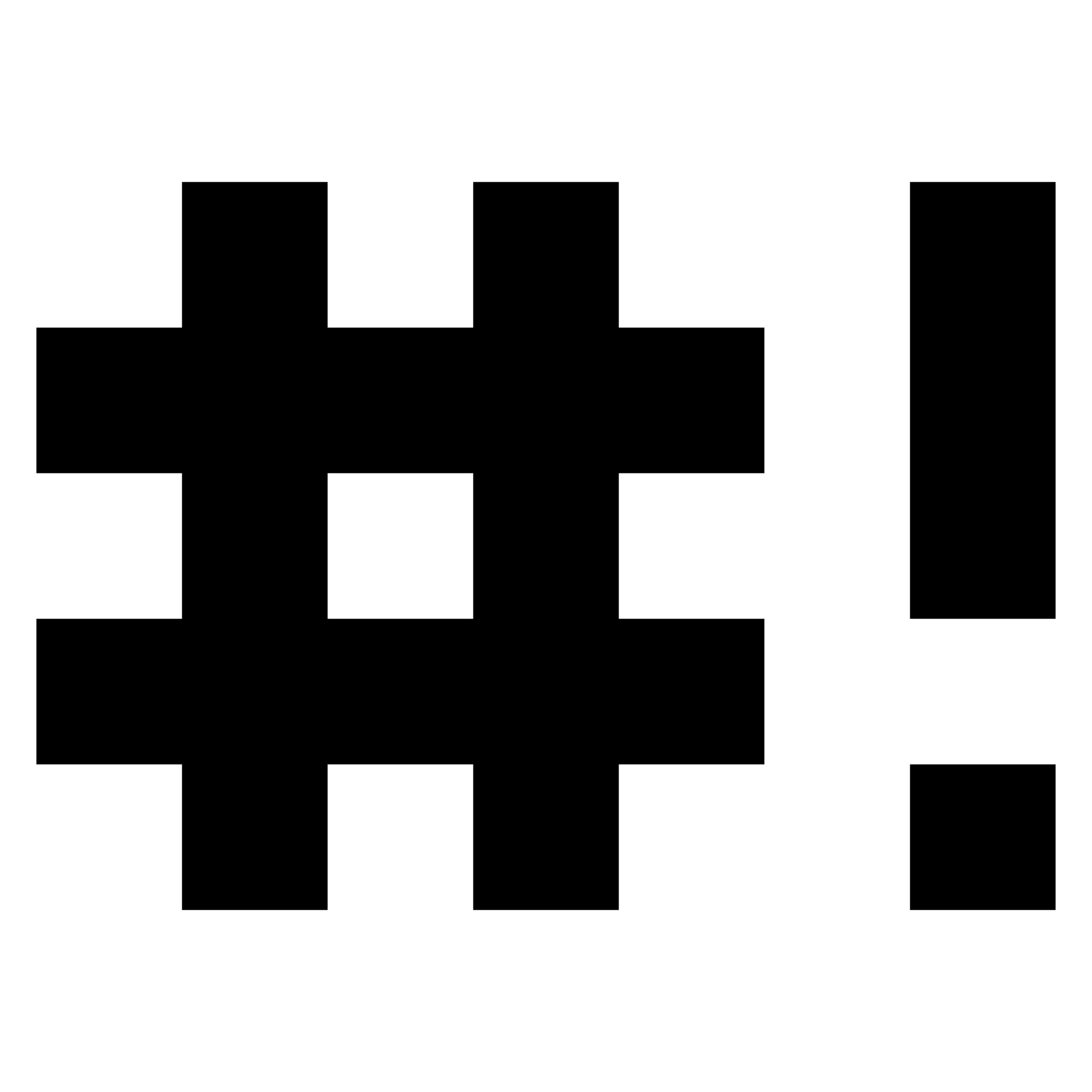More Networking Tricks
I consider the residential gateway overloaded. Your ISP is in the business of selling you the cheapest possible computer component to be a gateway device. Current devices also include a WiFi radio to double as home access point. By setting up a Raspberry Pi as your DHCP server and DNS forwarder, you can remove that… Read more »