Jed Reynolds has been known to void warranties and super glue his fingers together. When he is not doing photography or fixing his bike, he can be found being a grey beard programmer analyst for Candela Technologies. Start stalking him at https://about.me/jed_reynolds.
Before you suggest that it is better to use a backup program like Bacula or Amanda, I shall insist that making backups from the command-line is mighty useful. In scenarios where you are running in an embedded system (Rpi, Beaglebone), or a headless server that you want to keep a minimum install footprint on, writing a just-fits backup script can often be the correct choice.
This will be the first of a series of backup articles: we will learn various aspects of the find command, and move onto ways of using rsync and find in conjunction. I’m totally sure it will be a killer trip, man.
A bunk trip for most people is reading the man page for find. It’s not a command you learn from the man page. Instead, there are numerous options and endless possibilities for confusion…unless you have a tutorial. So, little dudes, let’s begin with the general features of find:
There’s a way to mark paths: -path and not descend them: -prune
You can make file name patterns with -name “*thing1*” and -iname “*thing2*”
And they can be combined with AND, OR and NOT: -a, -o, !
But don’t stop there. ALL aspects of the unix-style file system can be queried. The most likely things we want to know are file type:-type and last modified time: -mtime.
Excellent! Or well, that’s the theory. Let’s do three beginner examples:
Find assumes the current directory, which is always the first argument.
cd ~; find -type f
That shows way too many files. Great for a first backup…not useful for a daily backup.
Getting sharper- What config files did we modify in the last day?
find .config -type f -mtime -1
and the last two days?
find .config -type f -mtime -2
You and I know we don’t backup every day: that’s just life. Being smart, we’ll use the date of our last backup to build up the list of files we have modified since our last backup. Getting gnarly:
find ~/.config -type f -newer /var/backup/home-jed-2014-12-11.tgz
I’ve done my best to keep this one simple. Next edition, we’ll be making more of our backup by taking less. Dwell on using the last command above, but on your home directory. Is that what you really want to back up? Let me know below in the comments section.
Grep is a utility to find string patterns in text files. I cannot show you all the magic that grep can perform. Often the stuff you want to find in a file is buried in a lot of crud you don’t want in the file. Web server files? Yeah. Those. Spreadsheets? Unfortunately, they get large too. Image files? Yes, those too! I’m going to focus on those towards the end. So, let’s review a few tricks…
Do you need the Regular Expressions?
Grep could be grep, fgrep, or egrep in the Linux world. If you’re looking for whole words or numbers and not doing a regular expression, you can save processor time by using fgrep.
Did it start with a “Capital Letter?” Get into the habit of using the -i switch with grep, to make your searches case-insensitive. This saves you time by making first runs get more matches.
Server Log Files
Your mom always told you to clean your room. Well, the logrotate utility is like cleaning your log file closet, but with cron. As a habit, I rotate my log files daily and compress them. Zgrep is a good way to grep through compressed log files. If you’re doing a simple search, you can make zgrep use fgrep behind it with the grep environment variable:
See that -l switch? That just lists the name of the file. If you’re hunting down date ranges of where strings are, this helps. Conversely, if you know the date range of the files you need to search, don’t bother grepping everything…avoid it if you can. “Globbing” is your friend:
Is file compression actually faster or slower? That depends on your processor and your disk bandwidth. If you have a 5400rpm laptop hard drive, the less blocks you read off the disk the better.
If you have an SSD, you might not notice. If you have a Raspberry Pi running on an SD card, disk is actually your arch rival and compression becomes very important. You can gain a lot on compression of text files. Decompression is not expensive for CPUs. Writing decompressed data back to disk is more expensive in terms of IO (input/output) and that’s why decompression seems slow. If you have a desktop processor, your base clock speed is so much faster than an SSD’s input bitrate that you won’t even notice. Use the compression.
Can you grep Pictures?
Yes. You can grep anything, even ISO files, but you’ll likely find a lot of useless crap. Best to use the “strings” utility on binary files before you start grepping for things. This will help filter out the binary data that isn’t character strings.
strings < img4123.jpg | grep ‘2015’
This is a way to paw through the EXIF data in an image to see if you took it this year. Neat, huh? You don’t need to learn any ExifTool syntax to do that. Let’s try it out in a folder with … uh … 408 images!
> ls *jpg | while read f ; do echo -n "$f " ; strings $f | grep -c 2015 ; done
2015-05-24-two-flowers-1920x1272.jpg 1
_img2746.jpg 3
_img2747.jpg 3
_img2748.jpg 3
_img2749.jpg 3
_img2759.jpg 3
_img2760.jpg ^C
Oh, I have plenty of SSD but that’s still taking a while. Why is that? Oh, I’m chewing through 2.9 GB of pictures. Let’s actually profile that more closely, by timing that run:
> time for f in *jpg ; do strings $f | grep -c 2015 >/dev/null ; done
real 1m15.339s
user 0m41.112s
sys 0m5.440s
Now let’s try that just reading an area of the file where we know the EXIF data is: at the start. We can be pretty safe in assuming that we’re not going to read more than 4K of data to find this. Let’s drop our caches and try this again.
su -c ‘echo 3 > /proc/sys/vm/drop_cache’
> time for f in *jpg ; do head -c4096 $f | strings | grep -c 2015 >/dev/null ; done
real 0m5.601s
user 0m0.308s
sys 0m1.812s
Wow, that’s impressive, huh? Why 4096? That’s 4KB, your standard Linux file system page size and block size for your file system.
Let’s tie that in with my image processing work-flow: ImgDate.sh is the wee utility I glossed over in the previous article about organizing my image files. You’ll recognize how this works now:
I begin with my standard guard clause and swing my perl wand at it. I also could have used sed or grep, but perl seems to work just as quickly and the regular expressions are easier to write. Also, perl allowed me to use positional parameters to output the format right where I found it.
There are places (like embedded systems) where Perl isn’t an option. In those places, this would have been my grep and tr equivalent.
> head -c4096 IMAG0656.jpg \
| strings | egrep -o '[0-9]{4}:[0-9]{2}:[0-9]{2}' \
| head -n1 | tr ':' '-'
2024-05-19
So, the less you can read off the disk, the faster grep is going to go.
Long week? Yeah, me too. I have my heavy metal Linux band in the motel room and no customers to attend to at the moment…let’s do some Bash scripting! Remember the “thumbnailing” script I did a few weeks ago? This is the script I use before doing thumbnails. It’s actually a bit more trippy and uses another script which I’ll cover in the next installment.
We have a guard: did we screw up our file name? That’s almost irrationally cautious, so you might feel justified in deleting that guard. The $$ symbol is a quick way to get your process ID (PID). You can use this for many things, but it is reasonably unique with low-frequency usage (that is, a few times a day).
You can only have 65535 process IDs, and there are 86400 seconds a day, so if you approach one process a second, you’ll get repeats. If we find an identical date file, let’s delete it anyhow and create a new one. (POP QUIZ: tell me a one-liner that does this.)
Turn that metal up! We’re about to “headbang” through a crazy lead solo of string manipulation:
ls *.jpg *.dng *.bmp *.tiff *.jpeg \
*.JPG *.DNG *.BMP *.TIFF *.JPEG 2>/dev/null \
| while read F
do
G=$( echo -n "$F" | perl -pe 'y/[A-Z]/[a-z]/' )
cmd="mv -v $F $G"
$cmd
done
Yeah! Let’s crush some upper-case file names! Why the 2>/dev/null though? Have you ever done an “ls * .txt” command just to get everything in your directory listed and followed by a warning: .txt: file not found ? Yeah. That error message, or those TIFF or JPEG files you probably won’t have will all give you that message. It’s a safe message to discard into /dev/null.
We’re taking each file name F, and piping it into perl and feeding it into the Sarlacc jaws of the y/// translator. This y/// operator is the perl equivalent to the ‘tr’ command: it translates one character pattern to another character pattern. We’re forcing all upper-case alphabetic characters into lower case characters. Why? Type in caps much? (The bassist does, the bastard.) Extra credit: give me the shell command that replaces that perl command.
Now G is the transformed name, and we just move the file from the original F value to the new G value. (POP QUIZ:Why, oh why would I assemble a string of this command? Could this be evidence of an erased echo statement?) Extra Credit: make this command safer for filenames with spaces in them.
Drum solo! We’re going to rattle out some dates with another wee utility called ImgDate.sh:
ls *.{jpg,dng,bmp,tiff,jpeg,gif,png} 2>/dev/null \
| while read F
do
echo -n "$F " >> $DateFile
~/bin/ImgDate.sh $F >> $DateFile
done
Remember that the >> operator appends to files and echo -n prints stuff without a newline. Pay attention to spaces. We’re immediately going to use this output in a loop:
cat $DateFile | sort | uniq \
| while read D
do
echo "D $D"
imgfile=`echo "$D" | awk '{print $1}'`
imgdir=`echo "$D" | awk '{print $NF}'`
if [ ! -d "$imgdir" ]
then
mkdir -v $imgdir
fi
mv -v $imgfile $imgdir
done
What, another external program…awk? Isn’t that the sound your drummer makes after the fifth shot of Jagermeister? Hell yeah. Awk loves to toss out column values, so $1 is anything in the first column. What did we put in the first column of DateFile? Oh yeah…the drummer, no, the image file name. The last column is always $NF. Pop Quiz:Why not $2 in the second column? Warning: Don’t ask where why the drummer is called NF, he’s shy. Extra Credit #2: what if the file name has spaces in it?
Now we need to clean the floor of our motel room: /tmp. Let’s wipe up $DateFile.
rm -f $DateFile
I’m going to drag the drummer off to the tour bus, but I’m going to leave you with one more puzzler: If I delete $DateFile at the end of this party, why do I bother deleting it at the start of the party as well? Think about it…
There have been a lot of news reports and blog posts that have been making waves in my pond lately: the too many Linux distros argument. I actually chimed in on this topic a few years ago by contributing with a post about how the landscape of Linux distros are like a garden. A garden of heirloom tomatoes, where each distro has a few weak areas and one or two exceptional qualities.
I think the logical conclusion to that discussion turned out to be The Linux Luddites podcast: where Joe, Paddy and Jesse reviewed about forty(?) distros. They came to the broad and obviously glaring conclusion that these distros are out there because they scratched an itch. Unfortunately, most of the distros were not an actual maintained commercial solution, current, or well tested. I think the tomatoes metaphor should actually be turned into the crab apple metaphor.
Conclusion? Freedom. Duh.
Question: is the future of independent Linux distributions forever going to wane now that we have some clear successes like Ubuntu/Debian, Fedora/Centos, and Arch?
In total, I have about 20 virtual hosts I take care of across a few workstations. On one system alone, I keep five running constantly, doing builds and network monitoring. At work, my Ubuntu workstation has two Windows VMs I use regularly. My home workstation has about eight: a mix of Fedora(s) and Windows. A lot of my Windows use is pretty brief: doing test installs, doing web page compatibility checking, and using TeamViewer. Sometimes, a VM goes bonkers and you have to roll-back to a previous version of the VM; and sometimes VirtualBox’s snapshots are useful for that. On my home workstation, I have some hosts with about 18 snapshots and they are hard to scroll through…they scroll to the right across the window… How insightful. Chopping out a few snapshots in the middle of that pile is madness. Whatever Copy on Write (COW) de-duplication they end up doing takes “fuhevvuh.” It’s faster to compress all the snapshots into a new VM of one snapshot.
What would make more sense than this is to actually use proper filesystem snapshotting. And I’m not talking about LVM. LVM has or had a limit of 256 snapshots per pool. I want hundreds at a minimum: every 15 minutes, every hour, every day, every week…at last count I had about 950+ snapshots on my VM host machine.
Start with some reasonable hardware first: I recommend getting an E3 system with ECC memory, two SSDs for boot and cache, and four 2TB or bigger hard drives for vm storage. Configure your Ubuntu install on your SSDs in a RAID1 mirror, and leave two empty partitions, one of 50M and another of 1GB, on them for later. I typically have a partition setup like so:
md0 /boot
md2 /
md3 /home
md5 blank 50MB, for ZIL
md6 blank 1GB for L2Arc
Don’t even bother to install your large drives until after Ubuntu is set up. I won’t bore you with any other Ubuntu details other than I recommend starting with Ubuntu Server and then adding MATE desktop later. That gives you the flexible partitioning and md-adm setup you’ll want to get the formatting right.
Now, Ubuntu’s all setup and you’ve got your tiny fonts setup for your terminal, right? Let’s continue “lower-down.” Get those four large drives installed. Power up. Crack open a sudo -s and we’ll get those serial numbers:
Never been here before? Good. Most of the time you don’t need to, but this is super useful if you ever need to get the serial numbers on your drives without powering down your machines. We’re here because ZFS is going to work more predictably with device IDs like serial numbers than /dev/sdX handles that might change between reboots. What? Yes, drives get assigned names in a way caused by semi-random drive power-up and reporting times to OS…leaving udev to guess names or assign them on first-come, first serve basis.
Don’t sweat. You’ve got X setup so you can copy-paste these things anyhow. Control-shift-C and Control-shift-V, remember?
Let’s install our ZFS. Start with getting dkim installed. Then get ubuntu-zfs installed. It will generate a bunch of spl library installs (that’s Solaris Portability Library) and re-generate your ramdisks to get those .ko objects going.
sudo apt-get install dkim
sudo apt-get install ubuntu-zfs
sudo update-grub2
sudo shutdown -r now
Reboot and make sure that you have the ZFS module loading on boot.
lsmod | grep zfs
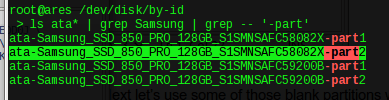
The actual ZFS command to establish your pool is going to get long. Open up an editor (pluma will be fine) and get your drive serial numbers ready to put into your version of this command:
Next let’s use some of those blank partitions we left to make a ZIL. That’s the ZFS intent log, a write cache on the SSDs.
We’ll make this safe and mirror them:
zpool tank add log mirror \
ata-Samsung_SSD_850_PRO_128GB_S1SMNSAFC58082X-part2 \
ata-Samsung_SSD_850_PRO_128GB_S1SMNSAFC59200B-part2
Now let’s make a Level-2 block cache:
zpool tank add log mirror \
ata-Samsung_SSD_850_PRO_128GB_S1SMNSAFC58082X-part2
ata-Samsung_SSD_850_PRO_128GB_S1SMNSAFC59200B-part2
This level-2 cache is also known as an L2ARC (adaptive replaceable cache). ZFS has default block caching in RAM as part of your zfs driver. This extends that to your SSD for when those blocks need to age out to L2 cache.
Almost done! Let’s check our progress using sudo zpool status -v. Yours should look similar to this:
Rest your brain for a minute. [Gets up, pours coffee, throws cat outside.]
The VirtualBox part is not so mysterious, but rather takes advantage of a technique known as link farming. Link farming is what you do when stuff doesn’t all live on the same partition. And putting things in separate partitions is essentially what I’m going to show you here. Like LVM, a volume is a file system, like one that lives on a partition, but in ZFS, your free space is for the whole pool and you don’t need to decide on partition sizes. You create a number of ZFS volumes and their size is only their disk usage.
We want to create a volume for each vm. When we snapshot each vm, we can roll back the vm snapshot and not change the filesystem of any other vm. Handy? Oh yeah. Some small details first:
zfs set compression=lz4 tank
zfs set sync=always tank/VMs
zfs create tank/temp
chown mylogin:mygroup /tank/temp
zfs set sharenfs=on tank/temp
zfs set sharesmb=on tank/temp
You can map /tank/temp as shared by a virtual host directory. There can be some complexity when doing nfs and samba shares with zfs. Enable the smb and nfs services first and then the share commands will work. [related]
Do you already have a running VirtualBox guest on another machine that you want to import? Great. I suggest exporting it to an ova appliance file first. Follow these tips to help get good command-line usability from starting and stopping your vms:
Enable remote desktop access and assign an easy to remember port. Definitely not the default; use something like 4500 or 8000. For each VM you add, you shall increment that number, allowing you to have rdp windows open to all your vm desktops if needed.
Rename your virtual machines to include this port number. This allows you to use virtualbox command-line with confidence: vboxmanage startvm --type=headless <portnum-name>
Create some useful aliases for starting your vms:
Name your sub-volumes differently for Windows v. Linux guests. You cannot move your windows guests after they get license keys. But Linux doesn’t care.
When you import the machine, suggest a path like /tank/VMs/fedora-19. After the import, make sure the vm is powered down. We’re going to switch some things around.
vboxmanage modifyvm fedora-19 9101-fedora-19
sudo zfs create tank/VMs/l_9101-fedora-21
sudo zfs set sync=always tank/VMs/l_9101-fedora-21
cd /tank/VMs
rsync -a --remove-source-files 9101-fedora-19 1_9101-fedora-21
rmdir 9101-fedora-19
chown mylogin:mygroup /tank/temp/l_9101-fedora-21
ln -s l_9101-fedora-21 9101-fedora-21
Whew! Lots of commands, but also a lot of benefits:
Our vm guest can be snapshotted and not interfere with other vm snapshot sets.
We have a reminder what the port is for RDP.
We have a reminder that this is a non-windows vm and we can move it safely.
If you created that function I pictured above, you can fire things up with:
startvm 9101-fedora-19
Here’s a picture of how I have my directory setup on ares:
This has worked well for me for most of the year. I can see some spots where I messed up, even. Can you spot them?
Feels like a lot of work. But really, I find this so much less maintenance down the road compared to using LVM. The best part is now: snapshots! We can install zfs-auto-snapshot and our snapshotting will begin automatically.
apt-get install zfs-auto-snapshot
sudo ls /etc/cron.hourly
sudo ls /etc/cron.d
See, the zfs-auto-snapshotter is going to start working within 15 minutes. If you need to tune your snapshots, you tune them per ZFS volume with ZFS volume attributes.
Who was it that said that Linux was like lumber? Was that Doc Searls? I don’t think it was Mad Dog. Well, I don’t see how the metaphor fits. Linux is not lumber, it’s a tool based on a legacy of programming. But none of the tools we use now (and I’m being really general) were not here when System V was new. We had to use our tool to make more tools.
What do you call that? No… Not a multi-tool. No, you call that a workshop. Linux is my workshop with my tools. Perl is my lathe for text, tcpdump is my oscilloscope for packets, and C is my blowtorch for welding libraries into new tools (I don’t actually like C).
Linux is a tool for craftswomen1: a workshop for data and logic carpentry. A machine shop for grinding out the programs that are the gears and sprockets for business. The lumber? You feed lumber into the machine. Our lumber is time. No time? No gizmo. Short a project on time? You get a wooden mallet for your business.
Now, that is a rich metaphor for Linux! One that conveys the best scenario for teaching people the nature of computers, too. The word workshop causes you to bypass thinking about the beige box on your desk and immediately skips your thinking to the tasks and tools you do with one instead. It emphasizes the multitude of skills and techniques needed for data and networking.
Hasn’t this all been solved, though? Can’t you get everything already on your iPhone or your Windows desktop? Sure, if you like hitting your problems with wooden mallets. (Ever try to run your enterprise web application on top of Microsoft Access? Yeah.)
Luckily, not all problems have been solved! This means jobs. This means hope. Don’t your kids use Linux yet? What are you waiting for? Teach your daughters2 Linux.
This website uses cookies to improve your experience. We'll assume you're ok with this, but you can opt-out if you wish.AcceptRejectRead More
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these cookies, the cookies that are categorized as necessary are stored on your browser as they are as essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may have an effect on your browsing experience.
This website uses cookies to improve your experience while you navigate through the website. Out of these cookies, the cookies that are categorized as necessary are stored on your browser as they are as essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may have an effect on your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.


{kind=link}
{kind=link}
{kind=link}
{kind=link}